The dream for high-performance computing (HPC) users is simple: pack as many GPUs into a rack mount box as possible to make everything run faster. While some servers can accommodate up to eight GPUs, most standard models typically have four GPU slots. While four modern GPUs can deliver impressive HPC performance, the question remains—can we go further? Let’s consider a setup with eight servers, each featuring four GPUs, totaling 32 GPUs. While it’s possible to utilize these GPUs for a single application using MPI across servers, this approach isn’t always efficient. Moreover, in shared computing environments, GPU nodes may remain idle because they’re restricted to GPU-only tasks, leaving CPUs and memory unavailable for other jobs.
Stranded Hardware
In the past, servers with a single processor, a moderate amount of memory, and one GPU were more granular, allowing resources to be used more effectively. Today, as servers cram more hardware—such as multi-core processors, large memory, and multiple GPUs—into a single box, sharing resources becomes trickier. A server with four GPUs may work well for GPU-specific jobs but often remains underutilized for other tasks, leaving CPUs and memory stranded. In simple terms, while packing more hardware into a single server can reduce overall costs, it may end up wasting valuable resources for HPC workloads.
Composable Hardware
The issue of stranded hardware has not gone unnoticed. Enter the Compute Express Link (CXL), a new technology designed to address this challenge. CXL is a standard for Cache-Coherent Interconnect for Processors, Memory Expansion, and Accelerators, currently rolling out in phases. This technology ensures memory coherency between the CPU’s memory and attached devices, enabling resource sharing for improved performance, lower software complexity, and reduced system costs.
While CXL is still in development, GigaIO has already integrated this functionality into its offerings. GigaIO has introduced a Single-Node Supercomputer capable of supporting up to 32 GPUs, all visible to a single host system. Unlike traditional setups where GPUs are partitioned across server nodes, GigaIO’s system allows all GPUs to be fully accessible and addressable by the host node. Using its FabreX technology, GigaIO has created a PCIe network that forms a dynamic memory fabric, allowing resources to be allocated in a composable manner.
GigaIO’s SuperNode
With FabreX technology, GigaIO recently demonstrated 32 AMD Instinct MI210 accelerators running in a single-node server. The SuperNode solution, available now, simplifies the system and can scale to include a variety of accelerator technologies, such as GPUs and FPGAs, without the latency, cost, or power overhead associated with multi-CPU systems. The key features of the SuperNode include:
- Hardware-agnostic support for any accelerator, including GPUs or FPGAs
- Capability to connect up to 32 AMD Instinct GPUs or 24 NVIDIA A100s to a single node server
- Ideal for significantly boosting performance in single-node applications
- Quick and easy deployment in large GPU environments
- Instant compatibility with TensorFlow and PyTorch libraries without requiring code changes
Andrew Dieckmann, Corporate VP at AMD, stated that the SuperNode system, powered by AMD Instinct accelerators, offers compelling total cost of ownership (TCO) for both traditional HPC and generative AI workloads.
Benchmarks Show Strong Performance
GigaIO’s SuperNode system was tested with 32 AMD Instinct MI210 accelerators in a Supermicro 1U server, powered by dual 3rd Gen AMD EPYC processors. Two key benchmarks, Hashcat and Resnet50, were used to evaluate performance:
- Hashcat: A workload that uses GPUs independently, showing perfect linear scaling up to 32 GPUs.
- Resnet50: A workload that uses GPU Direct RDMA or peer-to-peer connections, where scaling efficiency drops slightly as the GPU count increases, with a 1% performance degradation per GPU. At 32 GPUs, the overall scalability reached 70%.
These results highlight a significant improvement in scalability when compared to the traditional approach of scaling GPUs across multiple nodes using MPI. In multi-node systems, GPU scalability often drops to 50% or less.
CFD Performance on the SuperNode
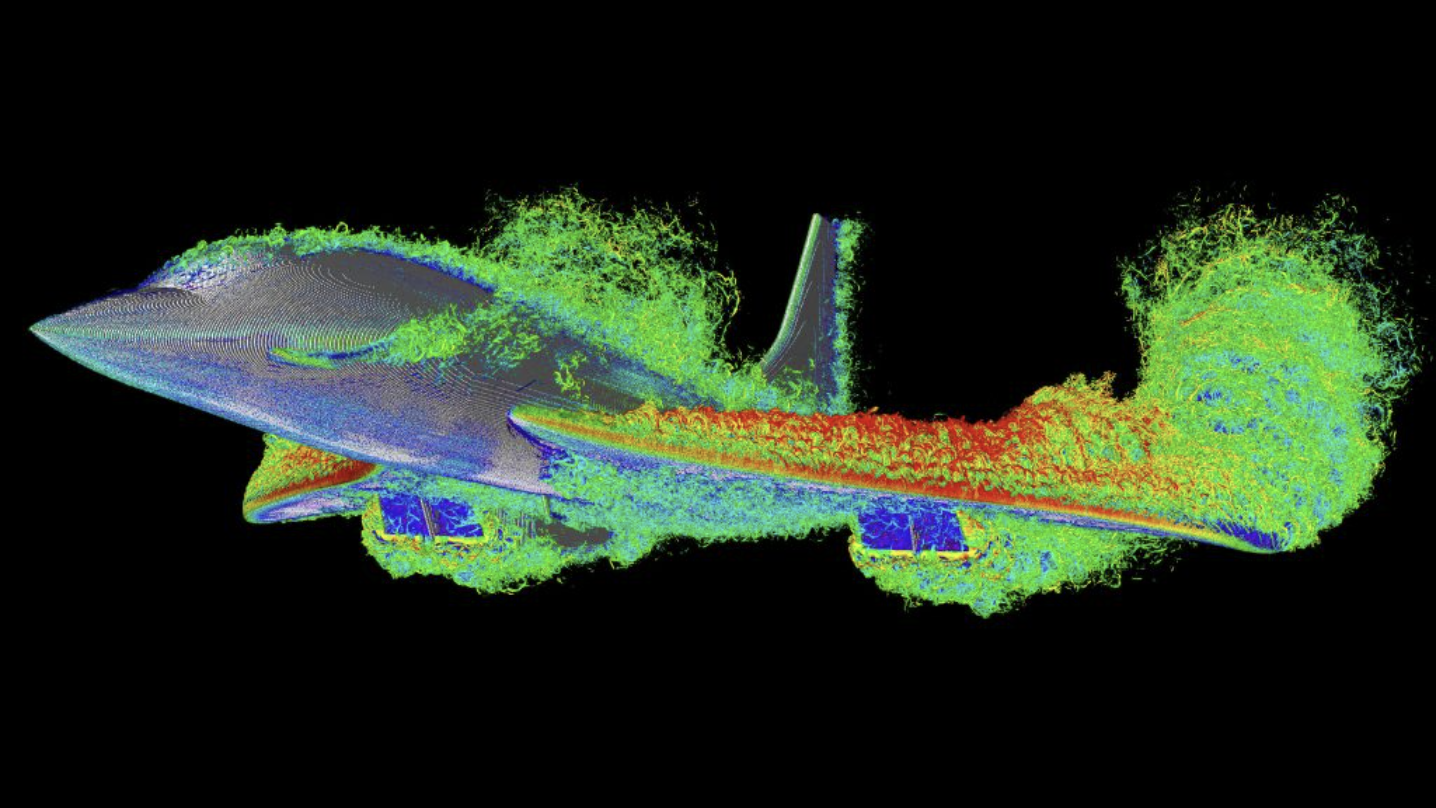
Dr. Moritz Lehmann recently shared his experience using the SuperNode for a Computational Fluid Dynamics (CFD) simulation. Over a weekend, Dr. Lehmann tested FluidX3D on the SuperNode and ran one of the largest CFD simulations ever for the Concorde, simulating the aircraft flying for one second at 300 km/h (186 mph) with a resolution of 40 billion cells. The simulation took just 33 hours to complete on 32 AMD Instinct MI210 GPUs, equipped with 2TB of VRAM in the SuperNode. Dr. Lehmann noted that commercial CFD simulations would take years to achieve the same results, but FluidX3D completed it in a weekend without requiring any code changes or porting. The system works seamlessly with 32-GPU scaling on AMD Instinct and an AMD Server, making it an incredibly efficient tool for large-scale simulations.